
⚡ Eleven v3 正式发布摘要
• Alpha 测试结束: 现已正式发布(Generally Available)
• 准确度质变: 错误率从 15.3% 大幅降至 4.9%
→ 无论是化学公式、数学算式,还是电话号码,统统能精准朗读!
大家好,这里是 Sonetho。⚡
大家期待已久的功能终于上线了。
此前一直处于 Alpha 测试阶段的 Eleven v3 模型,从今日起正式进入一般可用(Generally Available)阶段。

根据 Sonetho 持续监测的结果,此次的 v3 模型不仅在自然度上更进一步,还内置了能够“深度理解上下文”的智能引擎。
它究竟带来了多大的性能飞跃?我们为您整理了官方核心数据与变更点。
1. 性能跨越:错误率降低 68%
首先值得关注的是错误率(Error Rate)的显著下降。
这是 ElevenLabs 团队针对 8 种语言、27 个类别进行内部基准测试后得出的结果。
📊 Eleven v3 性能指标
- 旧版本错误率: 15.3%
- v3 错误率: 4.9%(整体错误率降低 68%)
- 用户偏好: 72% 的测试参与者认为 v3 表现优于旧版本
这不仅仅是音质的提升,更意味着 AI 现在拥有了“准确理解文本的能力”,表现已非常接近真人水平。
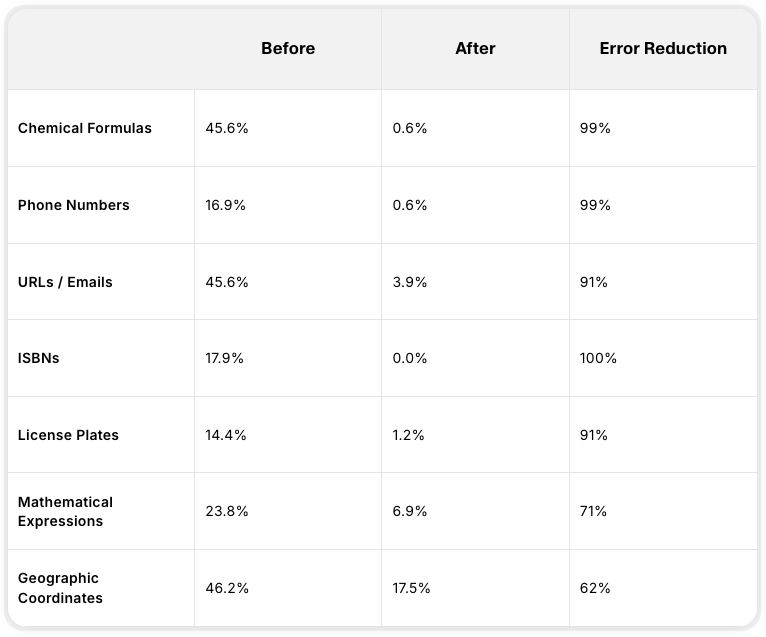
2. 关键进化:各类别准确度分析
在使用之前的 AI 语音模型(如 v2、Turbo 等)时,您或许曾遇到过让人头疼的情况:比如 AI 将电话号码乱读,或者机械地把化学分子式按英文字母逐个拼读出来。
在全新的 Eleven v3 中,这些问题已得到近乎完美(准确率 99% 以上)的解决。
| 类别 | 旧错误率 | v3 错误率 | 改进幅度 |
|---|---|---|---|
| 化学式 (Chemical) | 45.6% | 0.6% | 降低 99% |
| 电话号码 (Phone) | 16.9% | 0.6% | 降低 99% |
| URL/邮箱 | 45.6% | 3.9% | 降低 91% |
| ISBN 书号 | 17.9% | 0.0% | 降低 100% |
* 特别是 ISBN 识别错误率达到 0%,这对有声书制作行业而言是一项重大革新。
3. 细节差异:懂得“语境感知”的 AI
为什么“上下文(Context)”如此重要?
因为同样的符号,在不同场景下的念法完全不同。v3 能够通过分析语境,准确读出符号背后的含义。
✅ 冒号(:)的智能解析
- 体育比分:
102:99→ 读作“一百零二比九十九” - 时间:
14:30→ 读作“十四点三十分”
✅ 货币与专业术语优化
- 输入:
¥250,000
- (之前):可能会出现误读
- (现在):精准读作“二十五万元” - 输入:
SO2(二氧化硫)
- (之前):可能读成“S-O-2”(字母拼读)
- (现在):自动识别为“二氧化硫”
⚠️ 使用前必读(重要)
1. 暂不支持 PVC(个人语音克隆)
目前 v3 模型仅适用于 默认语音(Default Voices) 和 语音设计(Voice Design)。很遗憾,它尚未应用于个人声音克隆(Professional Voice Cloning, PVC)。
官方表示未来会逐步加入支持。
2. 分批推送 (Rolling Update)
“我的账号里怎么没看到 v3 选项?” → 请别担心!
目前正在全球范围内根据地区和账号分批次开放。若尚未看到选项,请耐心等待,几天内将覆盖全量用户。
总结:现在,生成即成品,无需二次剪辑
无论您是 YouTube 内容创作者、教育资料开发者还是有声书制作者,Eleven v3 都是您不可或缺的利器。
您再也不需要为了修复 AI 的语病而反复剪辑音频,也不需要强行修改原始文本来迁就 AI 了。
现在就前往 ElevenLabs 控制台,将模型切换为 [Eleven v3],亲自感受显著提升的朗读准确度吧!
※ 以上链接为 Sonetho 推广合作链接。
以上就是 Sonetho 为您带来的最新报道。 ⚡