
⚡ Eleven v3 正式リリース要約
• アルファテスト終了:ついに正式バージョン(GA:一般提供開始)として一般公開
• 精度に大革命:エラー率が15.3%から4.9%へと劇的に減少
→ 化学式、複雑な数式、さらには日本の電話番号や住所まで完璧に読み上げます!
こんにちは、Sonethoです。⚡
ついに、待望の瞬間がやってきました。
これまでアルファ(Alpha)テスト段階にあったEleven v3モデルが、本日より正式リリース(Generally Available)されました。

Sonethoで継続的に検証を重ねてきた結果、今回のv3モデルは単に「自然に話す」というレベルを超え、「文脈を理解する高度なインテリジェンス」が搭載されていることを強く実感させられます。
果たしてどれほど進化したのでしょうか? 公開された公式データと主な変更点をわかりやすく徹底解説します。
1. 圧倒的な性能向上:エラー率が68%減少
まず最も注目すべきは、エラー率(Error Rate)の劇的な減少です。
ElevenLabsチームが8つの言語、27のカテゴリーを対象に実施した内部ベンチマークテストの結果をご紹介します。
📊 Eleven v3 性能指標
- 従来モデルのエラー率: 15.3%
- v3のエラー率: 4.9%(全体のエラーが68%減少)
- ユーザーの好感度: テスト参加者の72%が従来バージョンよりもv3を支持
これは単に声の質感が向上しただけでなく、テキストを「正確に読み上げる能力」が人間に極めて近いレベルに達したことを意味しています。
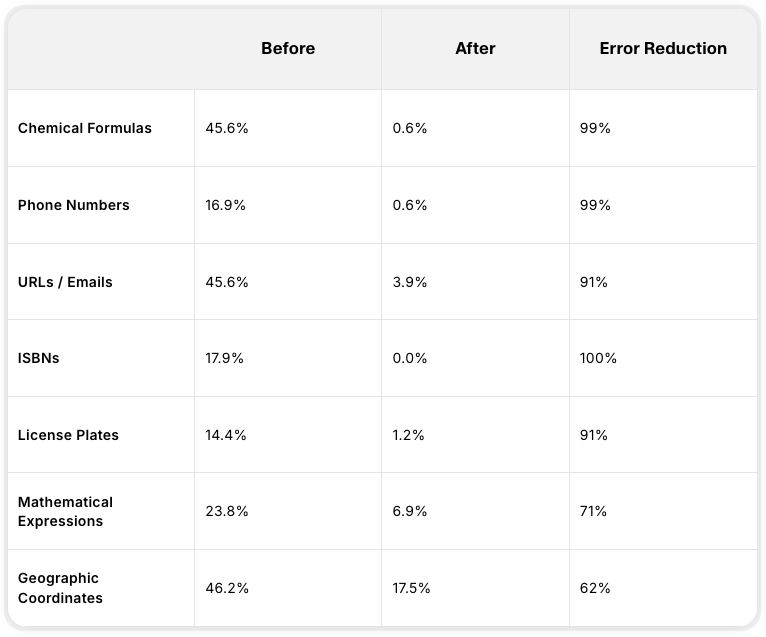
2. 具体的に何が変わったのか?(カテゴリー別精度分析)
従来のAI音声モデル(v2やFlash v2.5など)を使いながら、もどかしさを感じたことはありませんか?
電話番号の読み上げが不自然だったり、化学式を単なるアルファベットの羅列として読んでしまったりする問題です。
今回のEleven v3では、これらの課題がほぼ完璧(99%以上)にクリアされました。
| カテゴリー | 従来のエラー率 | v3のエラー率 | エラー減少率 |
|---|---|---|---|
| 化学式 (Chemicals) | 45.6% | 0.6% | 99% 減少 |
| 電話番号 (Phone Numbers) | 16.9% | 0.6% | 99% 減少 |
| URL・メールアドレス | 45.6% | 3.9% | 91% 減少 |
| ISBNコード | 17.9% | 0.0% | 100% 減少 |
* 特にISBN(国際標準図書番号)のエラー率0%達成は、オーディオブック制作において革命的です。
3. ディテールの違い:文脈を正確に読み解くAI
なぜ「文脈(Context)」の理解がそれほど重要なのでしょうか?
同じ記号や数字であっても、前後の文脈によって日本語の適切な読み方が変化するからです。
v3は文章の前後関係を正確に把握し、記号や助数詞を適した表現に解釈して発音します。読み間違いが発生しやすかった「4(し/よん)」や「7(しち/なな)」の判別、助数詞(〜本:いっぽん/にほん/さんぼん等)の処理能力も大幅に向上しました。
✅ コロン(:)の完璧な解釈
- スポーツのスコア:
102:99→ 「102対99(ひゃくに たい きゅうじゅうきゅう)」と正しく認識 - 時刻表記:
14:30→ 「14時30分(じゅうよじ さんじゅっぷん)」とスムーズに認識
✅ 通貨および専門用語の処理精度向上
- 入力:
¥250,000
- (従来モデル): 記号を誤読して不自然に読んだり、桁数を読み間違えたりする現象が発生
- (v3モデル): 「二十五万円(にじゅうごまんえん)」と完璧に認識して発音 - 入力:
SO2(二酸化硫黄)
- (従来モデル): 「エス・オー・ツー」と単にアルファベットのまま読み上げ
- (v3モデル): 「二酸化硫黄(にさんかいおう)」または「Sulfur Dioxide(サルファダイオキサイド)」と、化学式として自動認識して発音
⚠️ 使用前の注意点(必ずご確認ください)
1. PVC(プロフェッショナル音声クローン)は現在未対応
現在、v3モデルはデフォルトボイス(Default Voices)およびボイスデザイン(Voice Design)でのみ利用可能です。
残念ながら、ご自身の声を学習させたPVC(Professional Voice Cloning)モデルには、現時点では適用されていません。
PVCへの適用は今後のアップデートで対応予定とのことです。
2. 順次配信(ローリングアップデート)
「自分のダッシュボードにまだv3が表示されない…」と焦る必要はありません。
現在、世界中で地域・アカウントごとに順次ロールアウトが進行しています。
まだ表示されていない場合でも数日中には適用されますので、楽しみにお待ちください。
総評:これからはテキストの「ルビ振り」や「先読み調整」なしで、そのまま使えます
YouTubeのナレーション、教材音声、オーディオブックなどを制作しているクリエイターにとって、Eleven v3は「選択ではなく必須」のモデルとなるでしょう。
不自然な読み間違いを修正するために音声ファイルを再生成したり、漢字の読み方をひらがなに書き直したりする手間が、ほぼゼロになるからです。
今すぐElevenLabsのダッシュボードでモデル設定を【Eleven v3】に変更し、劇的に進化した読み上げ精度を体験してみてください!
※ 上記リンクは、Sonethoの公式提携リンクです。
以上、Sonethoでした。 ⚡