
「Voice Design(ボイスデザイン)で作った声、トーンはすごく良いのに…」
いざ日本語を喋らせてみると、カタコトの「外国人風の発音」になってしまい、
実用レベルに達せず諦めてしまったことはありませんか?
本日、Sonethoが公開する「音声合成テクニック」さえマスターすれば、
この世に存在しない完全オリジナルの声に、極めて自然な日本語の発音を
同時に宿すことができます。
「もう、誰かと被るような『ありきたりな声』からは卒業しましょう!」
こんにちは。Sonethoです。 ⚡
ElevenLabsには、「Voice Design(ボイスデザイン)」という画期的な機能があります。
性別、年齢、アクセントを指定するだけで、AIがランダムに新しい声を生成してくれる、いわば「声優ガチャ」のようなシステムです。
しかし、これには大きな弱点があります。それは、「日本語のイントネーション」への最適化がまだ発展途上である点です。
そこで今回は、Voice Designの弱点(発音やイントネーションの不自然さ)を、技術的なアプローチで完全に克服する「必勝戦略」を公開します。
1. Voice Designとは?(AI声優ガチャの仕組み)
一言で言えば、「この世に存在しないオリジナルの声をゼロから創造する機能」です。
事前の録音ファイル(音声データ)も一切不要。ボタンをクリックするだけで、AIが瞬時にまったく新しい音声を生成します。著作権や肖像権の心配をすることなく、「ブランド専用のオリジナルボイス」を持てる最も確実な方法です。
▲ 性別、年齢、アクセントを設定し、「Generate Voice」をクリックするだけで、瞬時に「新しいキャラクターの声」が誕生します。
💡 ElevenLabs公式ガイド直伝の裏技
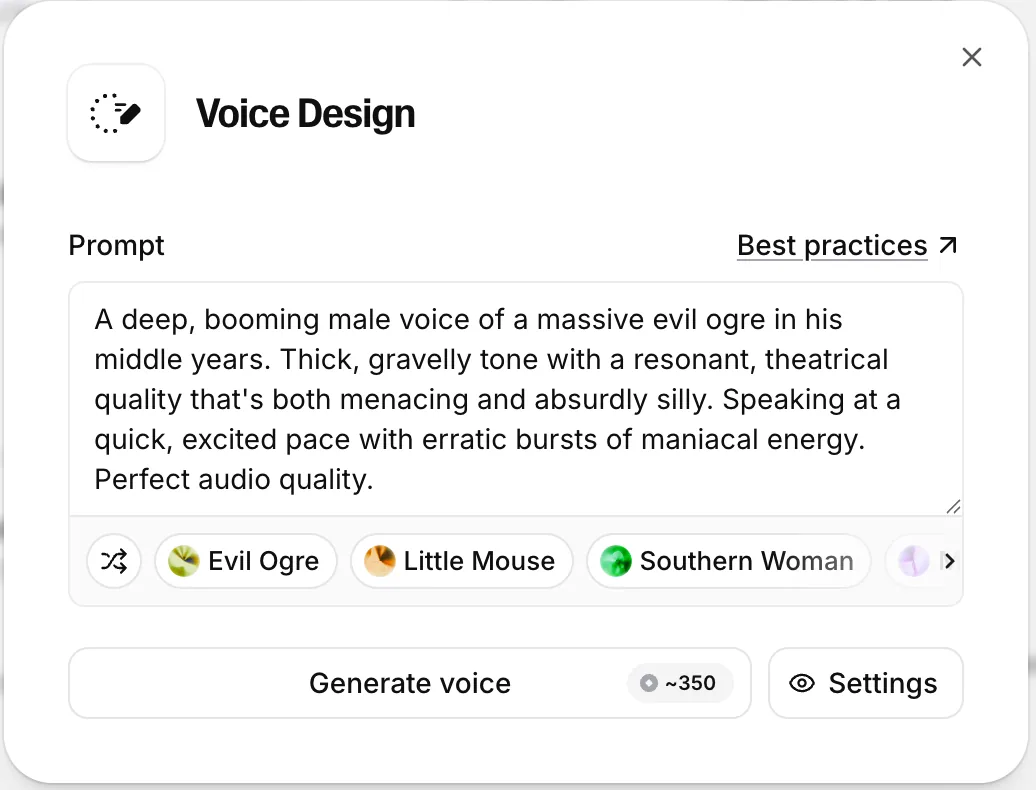
- プロンプト(Prompt)入力: 単に短い単語を指定するよりも、"An old British man with a raspy voice"(かすれた声のイギリス人老紳士)のように、特徴を具体的に入力するのがコツです(日本語で入力しても問題ありません!)。
- 魔法のキーワード(Magic Keyword): プロンプトに"Perfect audio quality"や"Studio quality"といったフレーズを加えると、生成される音質が劇的に向上します(逆に、あえてトランシーバー風のざらついた音質に仕上げることも可能です)。
🚨 注意!「プレビュー(Preview)の良さに惑わされないでください」
Voice Designを実行した際に提示される「3つのサンプル」は、最新のAIモデルが適用された極めてハイクオリティな音声です。
しかし、いざその中から気に入った声を選んで日本語テキストを喋らせてみると、初期設定が旧世代の基本モデル(Eleven Multilingual v2)になっているため、どこか教科書を棒読みしているような「ロボット感」の強い不自然な音声になってしまいがちです。
特に、数字の「4(し/よん)」や「7(しち/なな)」の読み分け、助数詞の「1本(いっぽん)」のアクセント、あるいは「JR」のようなアルファベット混じりの固有名詞など、日本語特有の複雑なニュアンスやイントネーションの壁に突き当たることが多々あります。
✅ 解決策:適切なモデルを選択する
- 音声生成画面にあるModel(モデル)設定を必ず確認してください。
- 最新のEleven V3(または用途に応じて超高速かつ軽量なEleven Flash v2.5)を選択することで、プレビュー時のような表現力豊かな「感情表現(演技トーン)」を引き出すことができます。
- さらに、設定画面でStability(安定性)の数値を少し下げる調整を施すことで、より豊かな感情表現が可能になります。
2. 正引なレビュー:「モデルを変えても、日本語の発音は完璧ではない」
生成モデルを最新のv3系に変更し、Stabilityを微調整することで、たしかに表現力は向上します。
しかし、それでもなお、完全に解決するのが難しい日本語特有の壁が立ちはだかります。
例えば、長文を読み上げさせた際に発生する「声の一貫性のブレ(途中で声質が変わる現象)」や、日本語特有の語尾が不自然に途切れてしまうノイズ、さらには細かなアクセントの違和感など、プロのクリエイターにとっては依然として妥協できないポイントが多いのが現状です。😩
3. この課題を100%解決する「音声合成アプローチ」
「声のトーン(音色)は完璧なのに、日本語の発音やイントネーションが不自然で実用に耐えない…」
そんな時に絶大な効果を発揮するアプローチが、ElevenLabsの【Voice Change(音声変換/Speech-to-Speech)】機能を巧みに活用した合成テクニックです。
🛠️ 音声合成テクニックの仕組み(役割分担)
- Voice Design(ボイスデザイン): 純粋な「声のトーン(音色・キャラクター性)」のみを抽出して担当(=器・外見)
- Voice Change(音声変換): 完璧な日本語の「発音・イントネーション・演技力」を担当(=魂・中身)
STEP 1. 「お手本」となる音声ファイル(Guide Audio)を用意する
まず、読ませたいテキスト原稿を用意し、日本語の発音が極めて自然な既存の高品質AI音声(または、ご自身で作成したPVC:プロフェッショナル・ボイスクローン)を使用し、ベースとなるお手本(ガイド音声)を一度書き出します。
STEP 2. 音声をマージする(Speech-to-Speech)
- Voice Settings: 音声生成の設定画面にて、Voice Designで作成した「あなただけのオリジナルキャラクター(声)」を選択します。
- Audio Upload: 先ほどSTEP 1で書き出した「お手本となるガイド音声ファイル」をアップロードします。
- Generate: あとは生成ボタン(Generate)をクリックするだけです!
💸 注意事項:クレジット消費に関する補足
このハイブリッドなアプローチは、「お手本(ガイド)音声の生成」と「Speech-to-Speechによる最終変換」の2ステップを踏むため、クレジットの消費量が実質的に約2倍になります。
しかし、「この世に二人と存在しない、完璧な日本語をフルスピードで流暢に操るオリジナルAI声優」を創り出せるというメリットを考えれば、十分に投資する価値がある戦略です。
おわりに:AIツールはアイデアと組み合わせ次第
Voice Designは、標準仕様のまま日本語テキストを読ませるだけではイントネーションに弱点がありますが、このように「技術とアイデア」を組み合わせることで、競合の誰も真似できない「あなただけのシグニチャー・ボイス(象徴的な声)」を完全な形で誕生させることができます。
現在、ElevenLabsではCreatorプラン(通常月額22ドル、約3,300円)が初月50%OFFとなるキャンペーンを実施しています。この機会に、十分なクレジット枠を活用して、自分だけの理想的な声をデザインしてみてはいかがでしょうか。(なお、本格的なビジネス・商用運用をお考えの方には、より大容量なProプラン(通常月額99ドル、約15,000円)も非常におすすめです)。
(※上記のリンクからご登録いただくと、初月最大50%の割引特典が自動的に適用されます。)
ビジネスの導入支援やご不明な点などがございましたら、いつでもお気軽に [email protected] までお問い合わせください!
以上、Sonethoでした。⚡