
⚡ Краткий обзор: Официальный релиз модели Eleven v3
• Конец бета-тестирования: Модель стала общедоступной (Generally Available).
• Революция точности: Уровень ошибок снизился с 15,3% до 4,9%.
→ Идеально озвучивает химические формулы, математические вычисления и сложные числовые данные!
Приветствуем, с вами Sonetho!⚡
Свершилось то, чего мы все так долго ждали.
Модель Eleven v3, которая до сегодняшнего дня находилась на стадии бета-тестирования, официально стала доступна всем пользователям (Generally Available).

Мы в Sonetho внимательно следили за обновлениями, и результаты впечатляют: в модель v3 встроен полноценный механизм «контекстуального понимания», что выводит качество синтеза на совершенно новый уровень.
Насколько всё стало лучше? Разбираем официальные данные и ключевые изменения до мельчайших деталей.
1. Впечатляющий прогресс: снижение частоты ошибок на 68%
Первое, на что стоит обратить внимание — это резкое снижение частоты ошибок (Error Rate).
Команда ElevenLabs провела масштабное бенчмарк-тестирование по 8 языкам и 27 категориям контента.
📊 Метрики производительности Eleven v3
- Предыдущий уровень ошибок: 15,3%
- Уровень ошибок v3: 4,9% (общее снижение ошибок на 68%)
- Предпочтения пользователей: 72% участников тестирования выбрали v3 вместо предыдущей версии
Это означает, что модель обрела способность считывать текст на уровне, максимально приближенном к человеческому.
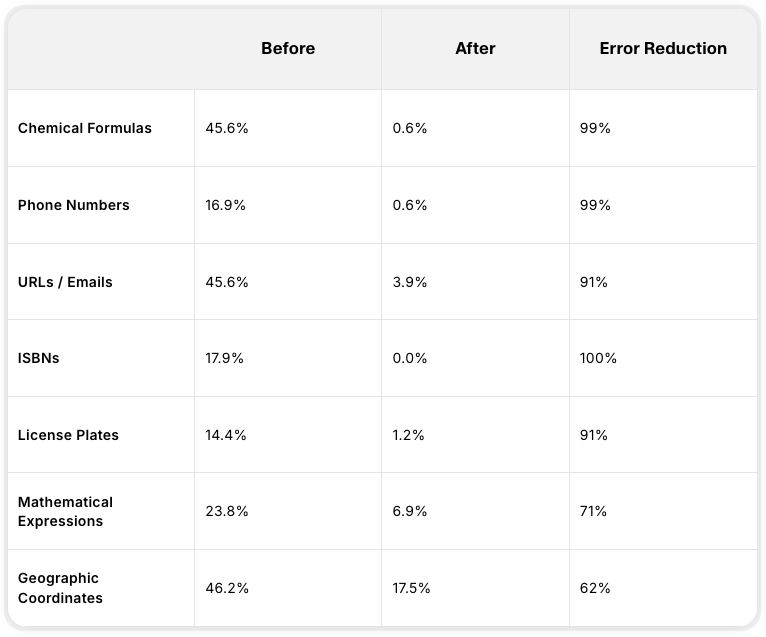
2. Что изменилось? (Анализ точности по категориям)
Многие из вас сталкивались с досадными неточностями в предыдущих моделях: например, странное произношение номеров телефонов или прочтение химических формул как обычного набора букв.
В Eleven v3 эти проблемы решены более чем на 99%.
| Категория | Было | Стало (v3) | Улучшение |
|---|---|---|---|
| Химия | 45,6% | 0,6% | -99% |
| Телефоны | 16,9% | 0,6% | -99% |
| URL/E-mail | 45,6% | 3,9% | -91% |
| Коды ISBN | 17,9% | 0,0% | -100% |
* Идеальная точность при чтении ISBN — настоящий прорыв для индустрии аудиокниг.
3. Внимание к деталям: ИИ, который понимает контекст
Почему «контекст» имеет решающее значение? Модель v3 анализирует окружение предложения и интерпретирует символы в соответствии с их смыслом.
✅ Умная обработка разделителей (:)
- Спортивный счет:
102:99→ читается как «сто два на девяносто девять». - Время:
14:30→ читается как «четырнадцать тридцать».
✅ Валюты и спецтермины
- Ввод:
¥250,000→ «Двести пятьдесят тысяч иен» (ранее возможны были ошибки). - Ввод:
SO2→ «Диоксид серы» (раньше произносилось по буквам как «эсс-о-два»).
⚠️ Важно знать перед использованием
1. Доступность функций
На текущий момент модель v3 оптимизирована для стандартных голосов (Default Voices) и дизайна голоса (Voice Design). Поддержка профессионального клонирования голоса (Professional Voice Cloning, PVC) для этой модели пока находится в стадии подготовки.
2. Поэтапное внедрение (Rolling Update)
Если вы еще не видите опцию v3 в дашборде — не паникуйте. Развертывание модели происходит поэтапно для всех аккаунтов по всему миру. Она появится в вашем личном кабинете в ближайшее время.
Итог: можно забыть о ручной правке текста
Если вы профессионально занимаетесь озвучкой видео, созданием учебных материалов или аудиокниг, Eleven v3 — это уже не опция, а необходимость для повышения продуктивности.
Вам больше не нужно принудительно адаптировать текст или использовать сложные транскрипции, чтобы заставить ИИ звучать корректно.
Заходите в дашборд ElevenLabs, выбирайте модель [Eleven v3] и убедитесь в прогрессе сами!
※ Ссылка выше является официальной партнерской ссылкой Sonetho.
С вами была Sonetho. ⚡