
⚡ Eleven v3 General Availability Summary
• Alpha Concluded: Eleven v3 has officially reached General Availability (GA)
• A Leap in Accuracy: Overall error rates slashed from 15.3% to a mere 4.9%
→ Flawless pronunciation of complex chemical formulas, equations, phone numbers, and homographs!
Welcome back to the Sonetho, creators! ⚡
The moment we've all been waiting for has officially arrived.
Following a highly successful alpha testing phase, the cutting-edge Eleven v3 model is officially Generally Available (GA).

Here at Sonetho, we’ve been putting this model through its paces.
And the verdict? Eleven v3 doesn't just sound incredibly human—it truly "grasps semantic context."
Just how big is this leap? Let's dive deep into the official benchmark data and game-changing upgrades.
1. A Massive Leap in Performance: 68% Reduction in Error Rates
First, let’s talk about accuracy. The drop in the overall error rate is nothing short of revolutionary.
The ElevenLabs team ran extensive internal benchmarks across 8 languages and 27 content categories. Here’s what they found:
📊 Eleven v3 Key Performance Metrics
- Legacy Model Error Rate: 15.3%
- v3 Error Rate: 4.9% (A 68% decrease in overall errors)
- User Preference: 72% of creators preferred Eleven v3 over older models
This means we are looking at more than just a natural cadence—its reading comprehension has reached near-human levels of precision.
2. What Actually Changed? (Category-by-Category Breakdown)
If you've used previous-generation AI voice models (like v2 or Turbo), you know the frustration.
They would often read phone numbers awkwardly, or butcher chemical formulas by spelling out individual letters.
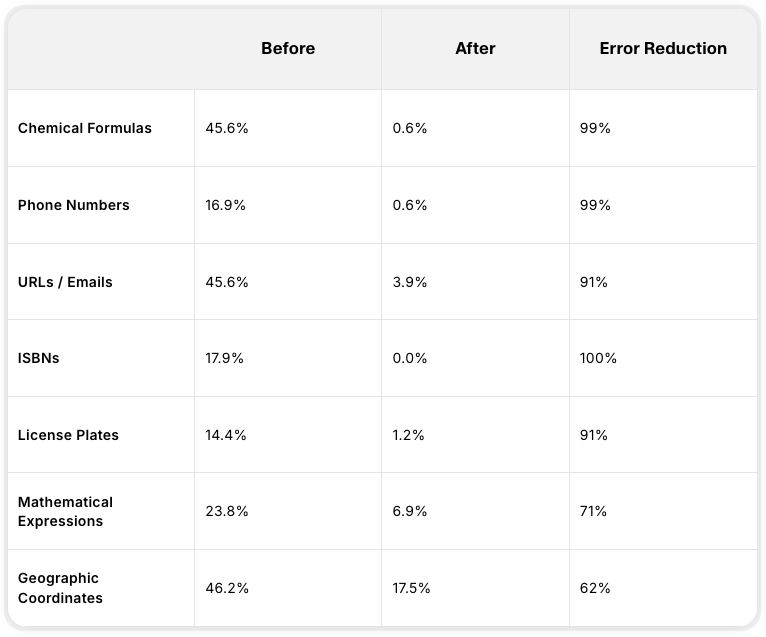
With Eleven v3, these legacy friction points have been virtually eradicated, boasting over 99% accuracy improvements in critical categories.
| Category | Legacy Error Rate | v3 Error Rate | Error Reduction |
|---|---|---|---|
| Chemical Formulas | 45.6% | 0.6% | 99% Reduction |
| Phone Numbers | 16.9% | 0.6% | 99% Reduction |
| URLs & Email Addresses | 45.6% | 3.9% | 91% Reduction |
| ISBN Codes | 17.9% | 0.0% | 100% Reduction |
* Achieving a 0.0% error rate on ISBNs is an absolute game-changer for audiobook publishers and creators.
3. The Power of Context: AI That Actually Gets It
Why does "context" matter so much in text-to-speech?
Because the English language is full of homographs, abbreviations, and symbols whose pronunciation shifts entirely depending on syntax and placement.
Eleven v3 dynamically analyzes the surrounding context to read text exactly like a seasoned voice actor.
✅ Flawless Colon (:) Interpretation
- Sports Scores:
102:99→ Pronounced naturally as "one hundred two to ninety-nine" - Time Formatting:
14:30or2:30 PM→ Reads flawlessly as "two thirty PM" without awkward, robotic pauses
✅ Smart Handling of Currency, Formulas, and Homographs
- Input:
$250,000or£250,000
- (Legacy Models): Clunky formatting reads or unnatural pauses.
- (Eleven v3): Flawless rendering as "two hundred fifty thousand dollars" or "two hundred fifty thousand pounds" with natural inflection. - Input:
SO2(Chemical Formula)
- (Legacy Models): Spelled out letter-by-letter as "S-O-two."
- (Eleven v3): Instantly recognized and read as "sulfur dioxide" in scientific contexts. - Input:
The CEO of NASA...
- Intelligently distinguishes acronyms from initialisms—reading "CEO" as individual letters ("C-E-O") but "NASA" as a single word ("nah-sah"). - Input:
I decided to read the book she read yesterday.
- Executes flawless homograph disambiguation, perfectly separating the present tense "read" (reed) from the past tense "read" (red) based on syntax. - Input:
déjà vu
- Pronounces foreign loanwords with native-level precision and authentic English-inflected nuance.
⚠️ A Quick Heads-Up Before You Get Started
1. PVC (Professional Voice Cloning) Support Pending
Currently, the Eleven v3 model is available exclusively for Default Voices and Voice Design.
For now, it cannot be applied to Professional Voice Clones (PVC). However, ElevenLabs has confirmed that PVC compatibility is on the roadmap and will roll out shortly.
2. Rolling Update in Progress
Can't see Eleven v3 on your dashboard yet? Don't panic!
ElevenLabs is deploying the model in phased rollouts globally.
If it hasn't appeared yet, it should land in your workspace within the next few days.
The Verdict: Say Goodbye to Clunky Phonetic Workarounds
For independent creators, podcasters, educators, and video editors, Eleven v3 is a massive productivity leap.
You no longer need to write awkward phonetic workarounds (like spelling out "C-E-O" to force the right pronunciation) or spend hours slicing audio files to correct mispronounced words.
Head over to your ElevenLabs dashboard, switch your generation settings to [Eleven v3], and experience the next generation of generative audio today!
Disclosure: The link above is an official affiliate link supporting Sonetho.
Until next time, keep creating! ⚡